# Setup - Run only once per Kernel App
%conda install openjdk -y
# install PySpark
%pip install pyspark==3.4.0
# restart kernel
from IPython.core.display import HTML
HTML("<script>Jupyter.notebook.kernel.restart()</script>")Collecting package metadata (current_repodata.json): done
Solving environment: done
==> WARNING: A newer version of conda exists. <==
current version: 23.3.1
latest version: 24.3.0
Please update conda by running
$ conda update -n base -c defaults conda
Or to minimize the number of packages updated during conda update use
conda install conda=24.3.0
## Package Plan ##
environment location: /opt/conda
added / updated specs:
- openjdk
The following packages will be downloaded:
package | build
---------------------------|-----------------
ca-certificates-2024.3.11 | h06a4308_0 127 KB
certifi-2024.2.2 | py310h06a4308_0 159 KB
openjdk-11.0.13 | h87a67e3_0 341.0 MB
------------------------------------------------------------
Total: 341.3 MB
The following NEW packages will be INSTALLED:
openjdk pkgs/main/linux-64::openjdk-11.0.13-h87a67e3_0
The following packages will be UPDATED:
ca-certificates conda-forge::ca-certificates-2023.11.~ --> pkgs/main::ca-certificates-2024.3.11-h06a4308_0
certifi conda-forge/noarch::certifi-2023.11.1~ --> pkgs/main/linux-64::certifi-2024.2.2-py310h06a4308_0
Downloading and Extracting Packages
openjdk-11.0.13 | 341.0 MB | | 0%
certifi-2024.2.2 | 159 KB | | 0%
ca-certificates-2024 | 127 KB | | 0%
ca-certificates-2024 | 127 KB | ##################################### | 100%
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
Note: you may need to restart the kernel to use updated packages.
Collecting pyspark==3.4.0
Using cached pyspark-3.4.0-py2.py3-none-any.whl
Collecting py4j==0.10.9.7 (from pyspark==3.4.0)
Using cached py4j-0.10.9.7-py2.py3-none-any.whl.metadata (1.5 kB)
Using cached py4j-0.10.9.7-py2.py3-none-any.whl (200 kB)
Installing collected packages: py4j, pyspark
Successfully installed py4j-0.10.9.7 pyspark-3.4.0
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[notice] A new release of pip is available: 23.3.1 -> 24.0
[notice] To update, run: pip install --upgrade pip
Note: you may need to restart the kernel to use updated packages.

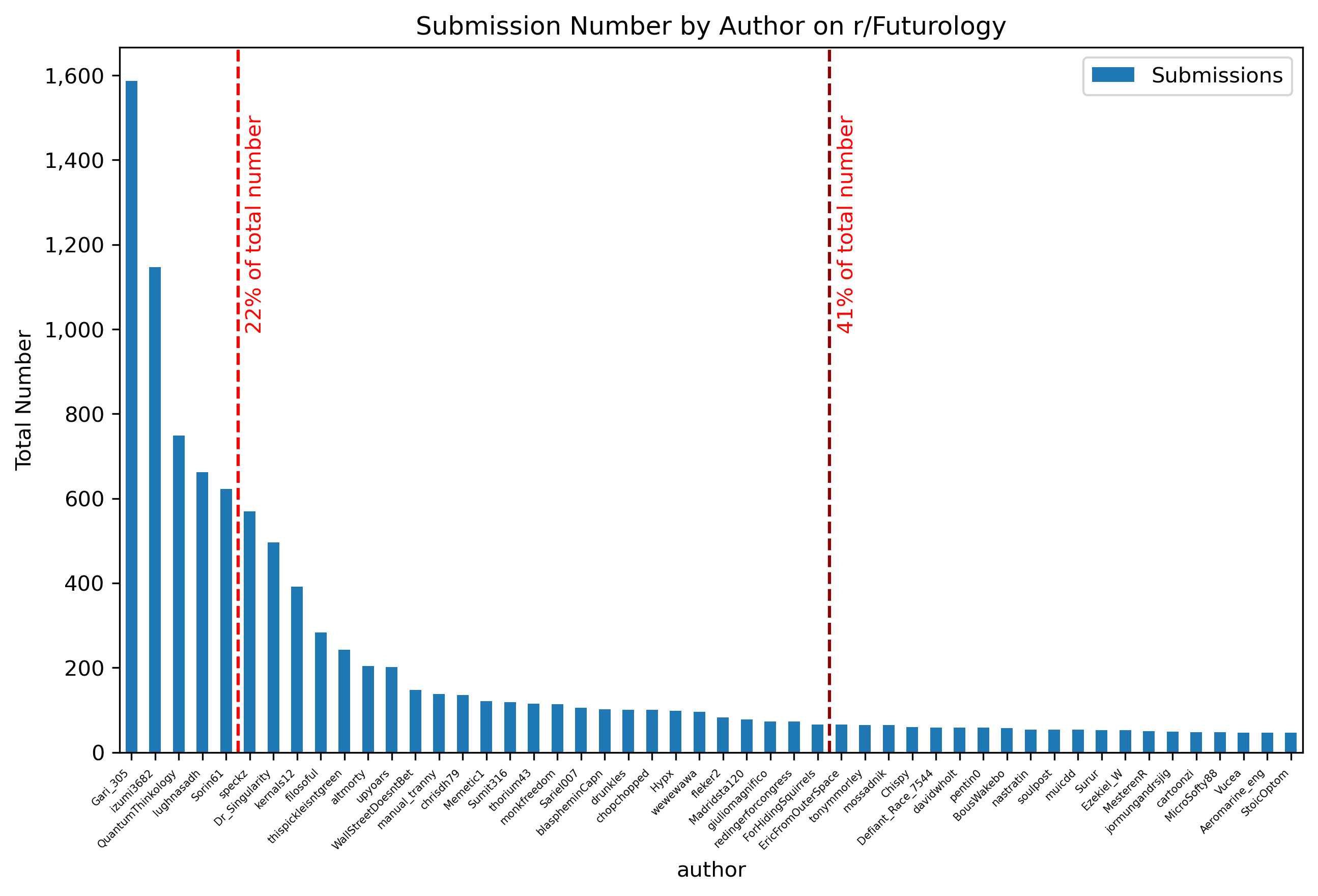
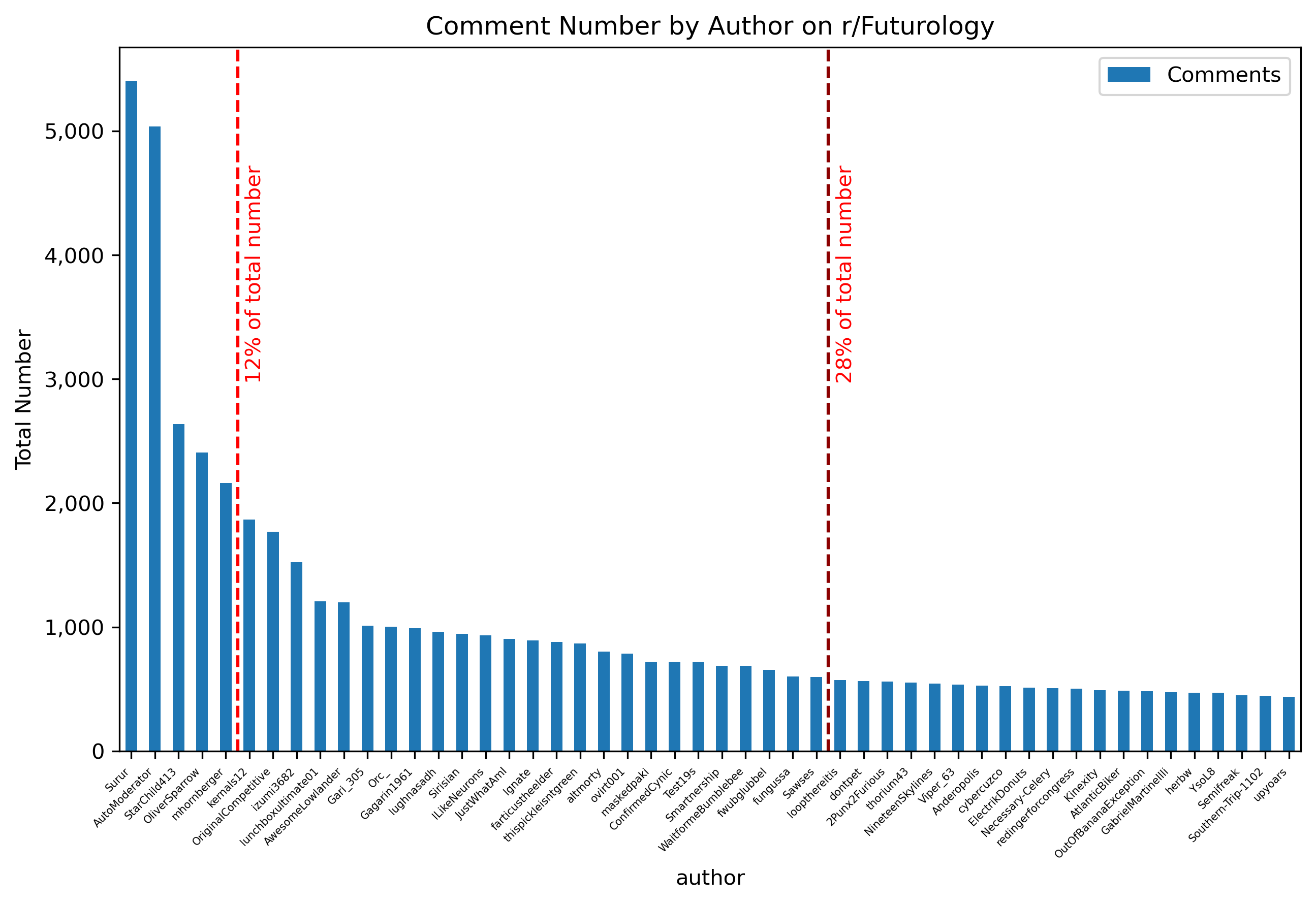
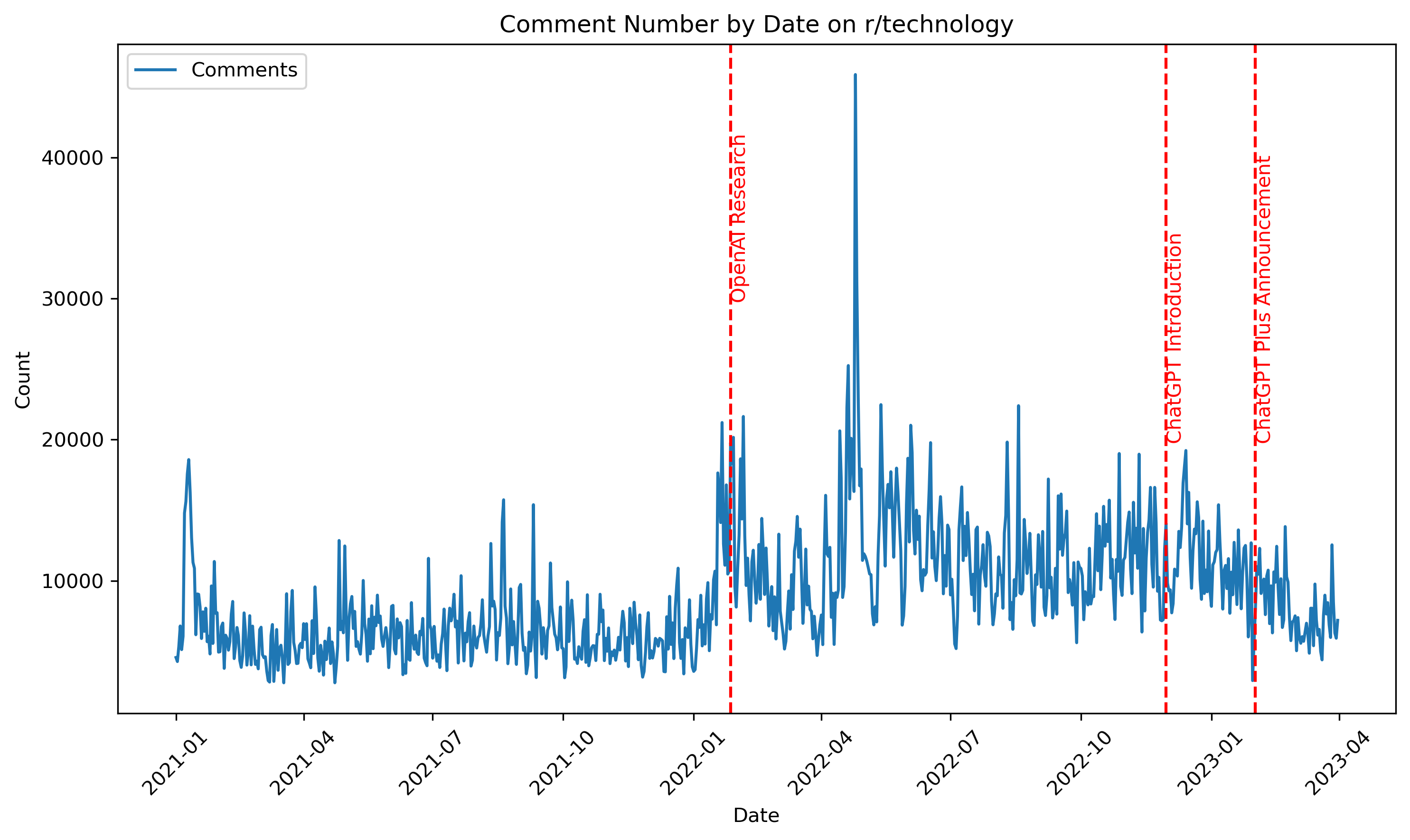
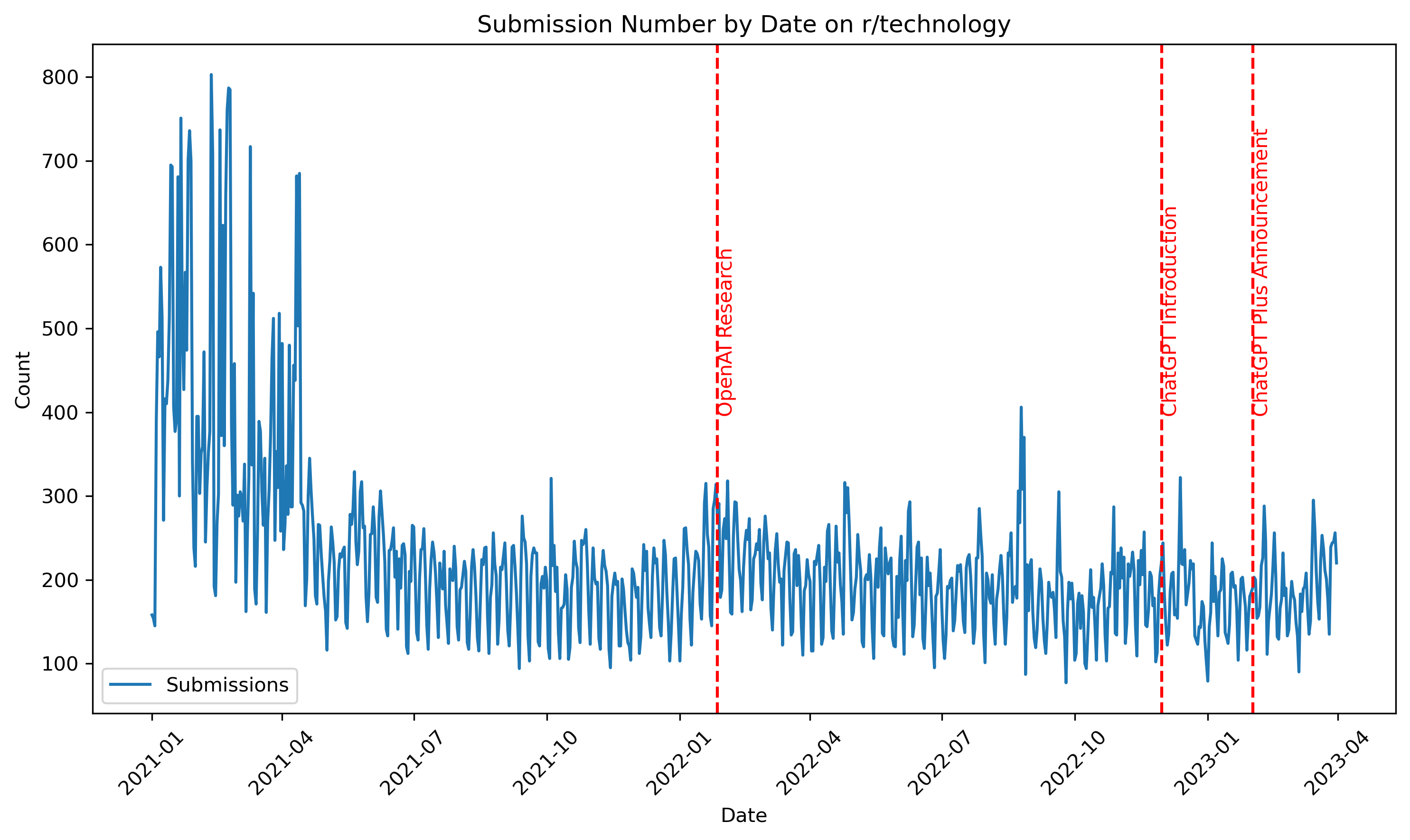
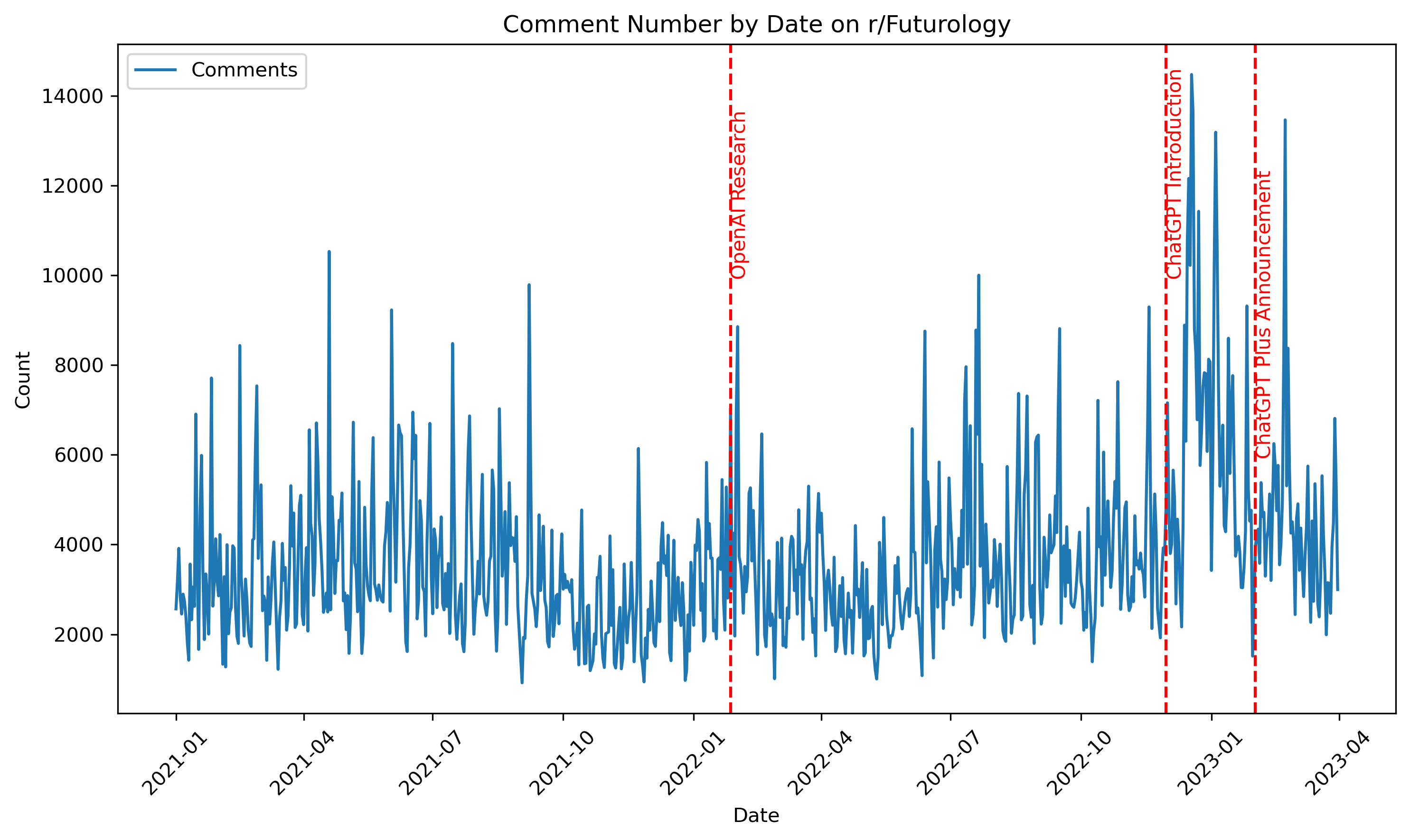
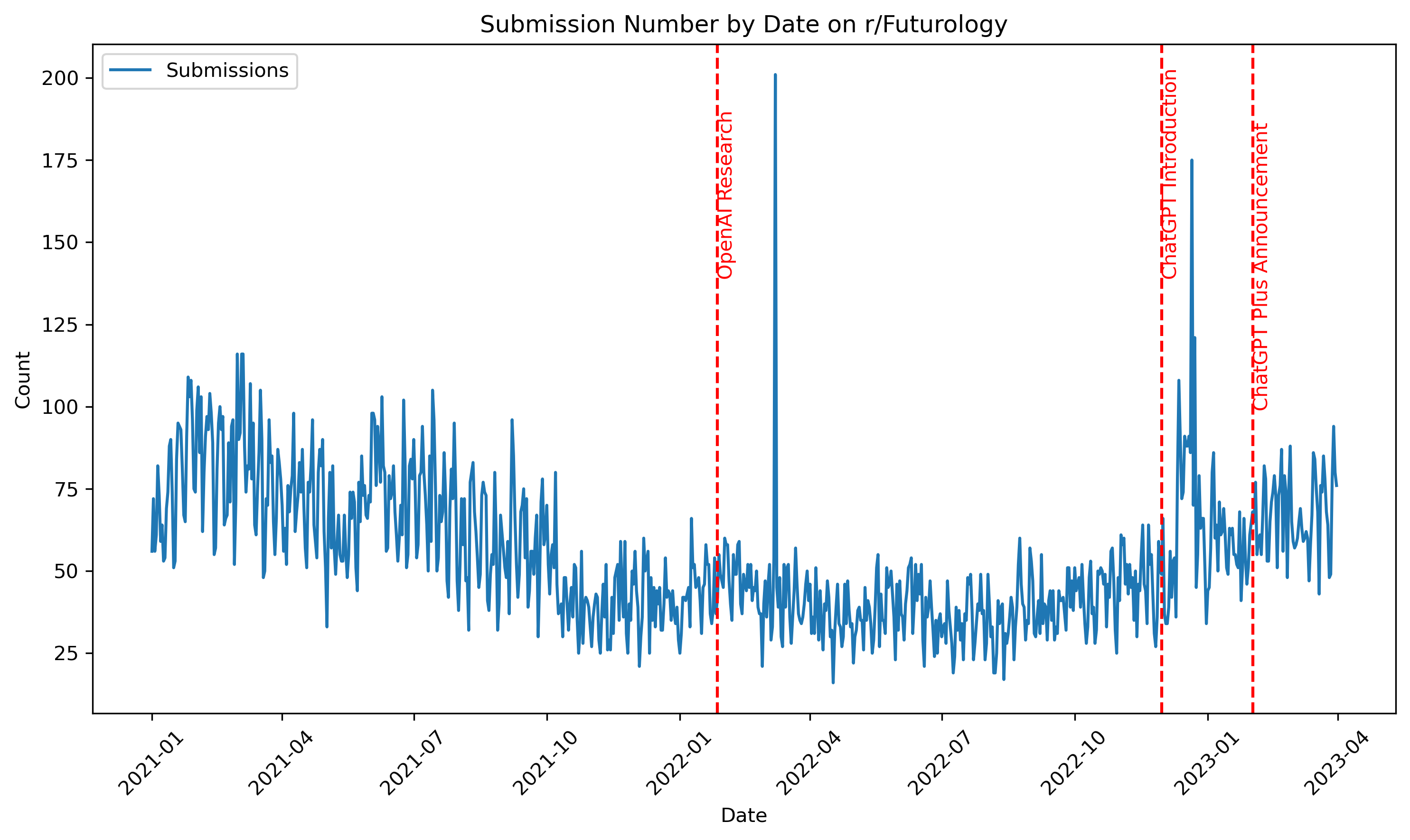
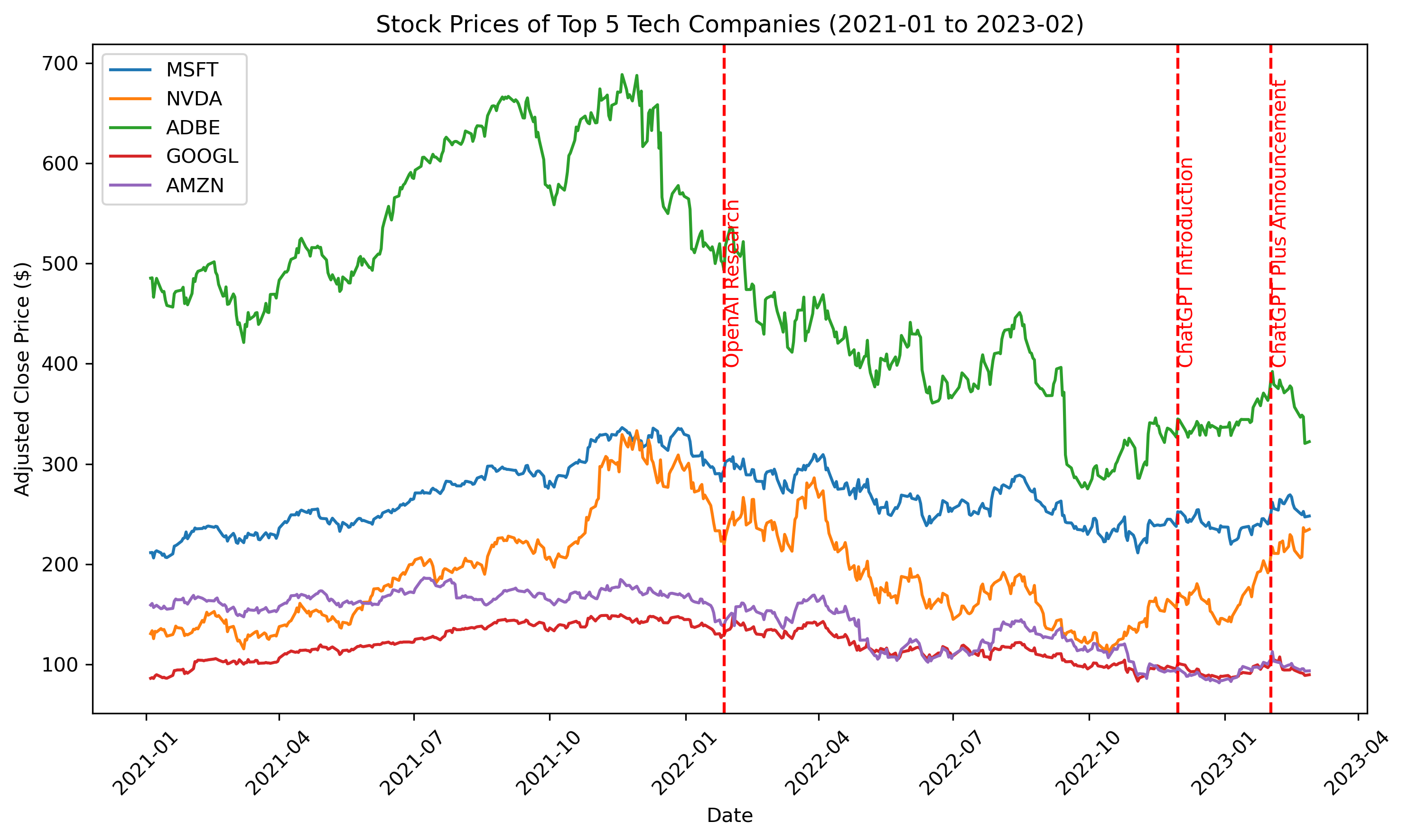
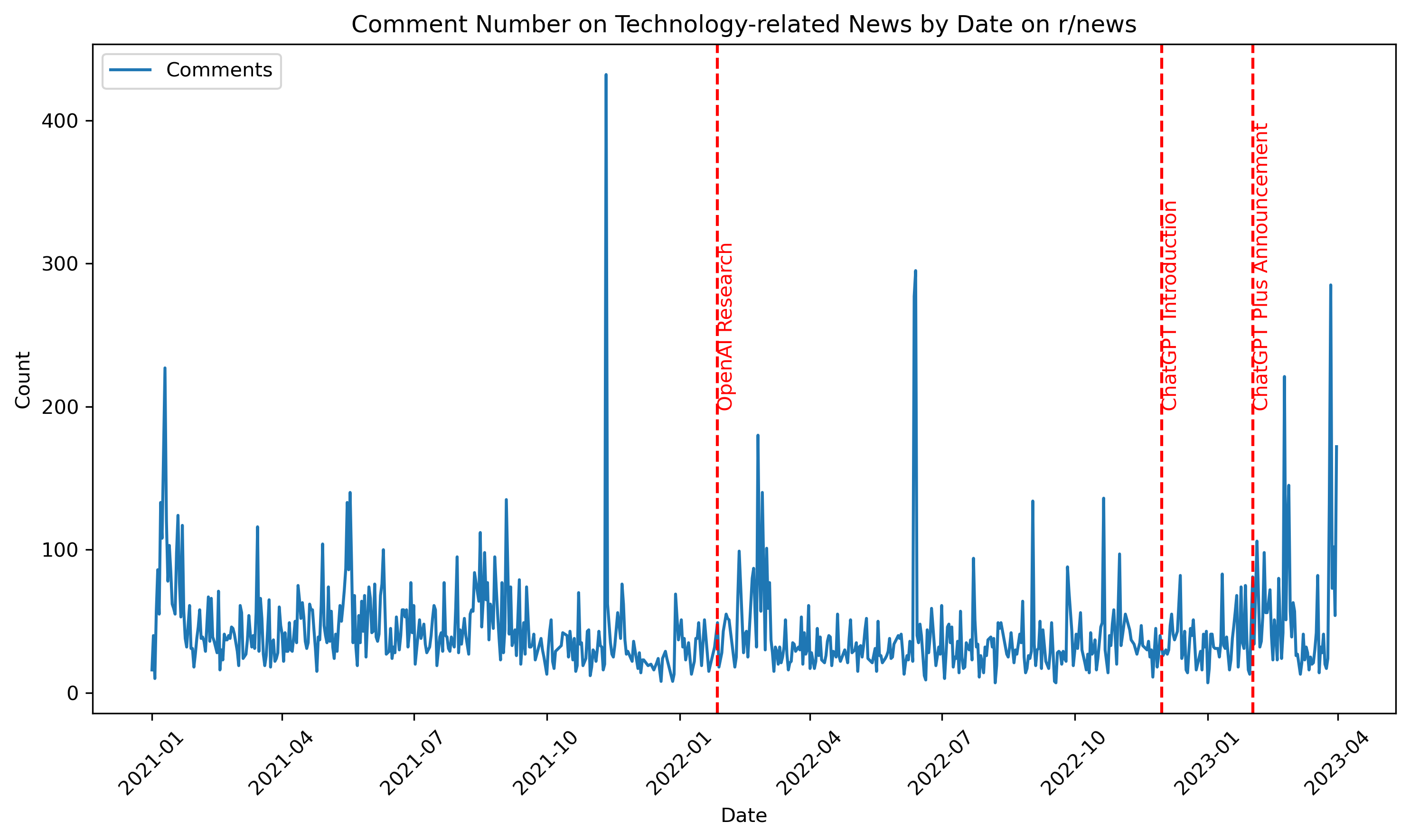
Comment Count