DataFrame[adserver_click_url: string, adserver_imp_pixel: string, archived: boolean, author: string, author_cakeday: boolean, author_flair_css_class: string, author_flair_text: string, author_id: string, brand_safe: boolean, contest_mode: boolean, created_utc: timestamp, crosspost_parent: string, crosspost_parent_list: array<struct<approved_at_utc:string,approved_by:string,archived:boolean,author:string,author_flair_css_class:string,author_flair_text:string,banned_at_utc:string,banned_by:string,brand_safe:boolean,can_gild:boolean,can_mod_post:boolean,clicked:boolean,contest_mode:boolean,created:double,created_utc:double,distinguished:string,domain:string,downs:bigint,edited:boolean,gilded:bigint,hidden:boolean,hide_score:boolean,id:string,is_crosspostable:boolean,is_reddit_media_domain:boolean,is_self:boolean,is_video:boolean,likes:string,link_flair_css_class:string,link_flair_text:string,locked:boolean,media:string,mod_reports:array<string>,name:string,num_comments:bigint,num_crossposts:bigint,num_reports:string,over_18:boolean,parent_whitelist_status:string,permalink:string,pinned:boolean,quarantine:boolean,removal_reason:string,report_reasons:string,saved:boolean,score:bigint,secure_media:string,selftext:string,selftext_html:string,spoiler:boolean,stickied:boolean,subreddit:string,subreddit_id:string,subreddit_name_prefixed:string,subreddit_type:string,suggested_sort:string,thumbnail:string,thumbnail_height:string,thumbnail_width:string,title:string,ups:bigint,url:string,user_reports:array<string>,view_count:string,visited:boolean,whitelist_status:string>>, disable_comments: boolean, distinguished: string, domain: string, domain_override: string, edited: string, embed_type: string, embed_url: string, gilded: bigint, hidden: boolean, hide_score: boolean, href_url: string, id: string, imp_pixel: string, is_crosspostable: boolean, is_reddit_media_domain: boolean, is_self: boolean, is_video: boolean, link_flair_css_class: string, link_flair_text: string, locked: boolean, media: struct<event_id:string,oembed:struct<author_name:string,author_url:string,cache_age:bigint,description:string,height:bigint,html:string,provider_name:string,provider_url:string,thumbnail_height:bigint,thumbnail_url:string,thumbnail_width:bigint,title:string,type:string,url:string,version:string,width:bigint>,reddit_video:struct<dash_url:string,duration:bigint,fallback_url:string,height:bigint,hls_url:string,is_gif:boolean,scrubber_media_url:string,transcoding_status:string,width:bigint>,type:string>, media_embed: struct<content:string,height:bigint,scrolling:boolean,width:bigint>, mobile_ad_url: string, num_comments: bigint, num_crossposts: bigint, original_link: string, over_18: boolean, parent_whitelist_status: string, permalink: string, pinned: boolean, post_hint: string, preview: struct<enabled:boolean,images:array<struct<id:string,resolutions:array<struct<height:bigint,url:string,width:bigint>>,source:struct<height:bigint,url:string,width:bigint>,variants:struct<gif:struct<resolutions:array<struct<height:bigint,url:string,width:bigint>>,source:struct<height:bigint,url:string,width:bigint>>,mp4:struct<resolutions:array<struct<height:bigint,url:string,width:bigint>>,source:struct<height:bigint,url:string,width:bigint>>,nsfw:struct<resolutions:array<struct<height:bigint,url:string,width:bigint>>,source:struct<height:bigint,url:string,width:bigint>>,obfuscated:struct<resolutions:array<struct<height:bigint,url:string,width:bigint>>,source:struct<height:bigint,url:string,width:bigint>>>>>>, promoted: boolean, promoted_by: string, promoted_display_name: string, promoted_url: string, retrieved_on: timestamp, score: bigint, secure_media: struct<event_id:string,oembed:struct<author_name:string,author_url:string,cache_age:bigint,description:string,height:bigint,html:string,provider_name:string,provider_url:string,thumbnail_height:bigint,thumbnail_url:string,thumbnail_width:bigint,title:string,type:string,url:string,version:string,width:bigint>,type:string>, secure_media_embed: struct<content:string,height:bigint,media_domain_url:string,scrolling:boolean,width:bigint>, selftext: string, spoiler: boolean, stickied: boolean, subreddit: string, subreddit_id: string, suggested_sort: string, third_party_trackers: array<string>, third_party_tracking: string, third_party_tracking_2: string, thumbnail: string, thumbnail_height: bigint, thumbnail_width: bigint, title: string, url: string, whitelist_status: string, created_date: string, created_time: string, cleaned_words: array<string>, final_words: array<string>, final_sentence: string, contains_chatgpt: boolean, contains_bard: boolean, contains_copilot: boolean, contains_deepmind: boolean, contains_waymo: boolean, contains_mobileye: boolean, contains_aurora: boolean, contains_oculus: boolean, contains_apple: boolean, contains_metaverse: boolean, contains_drone: boolean, contains_dog: boolean, contains_humanoid: boolean, contains_roomba: boolean]



Comments
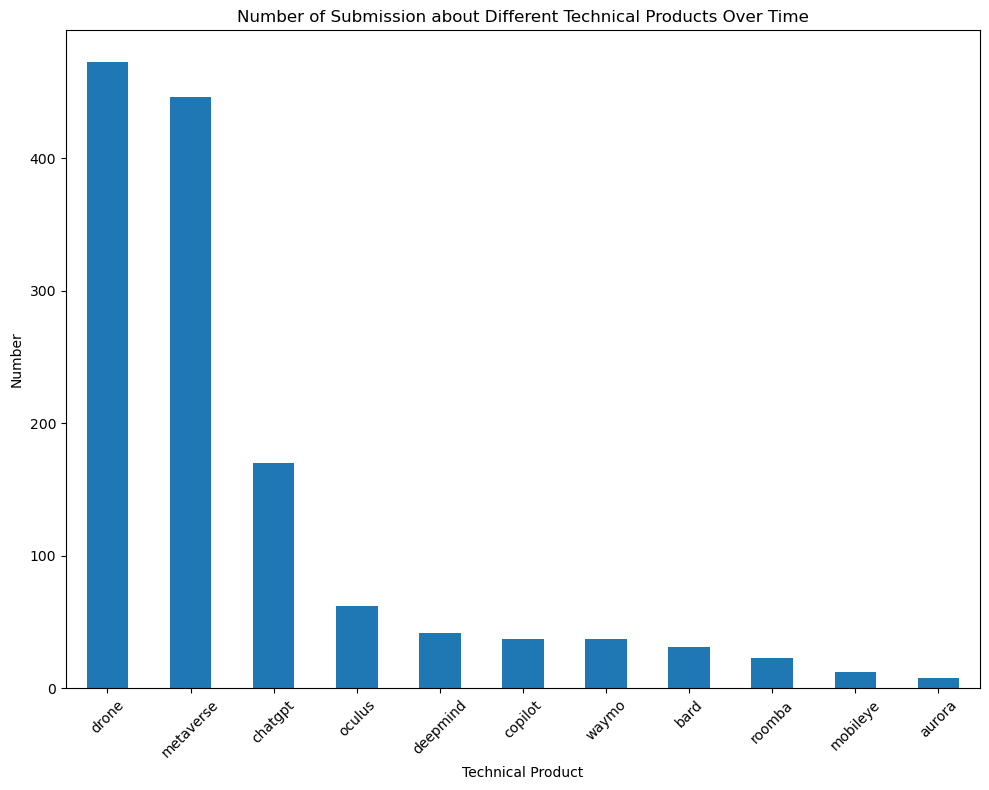
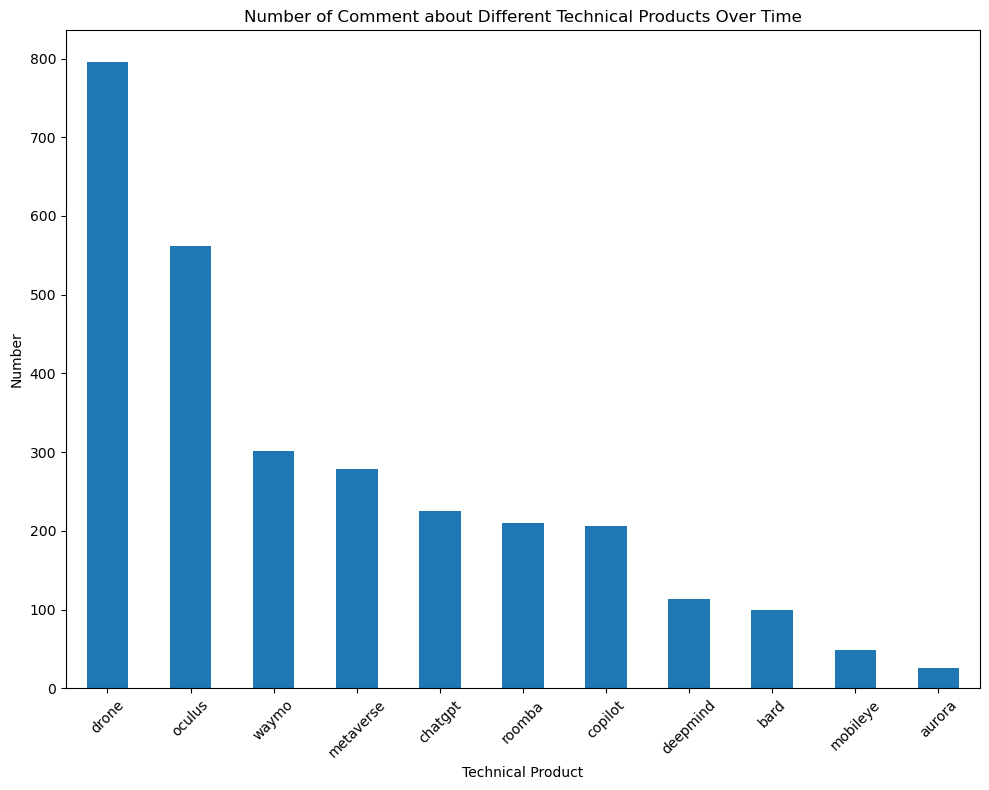
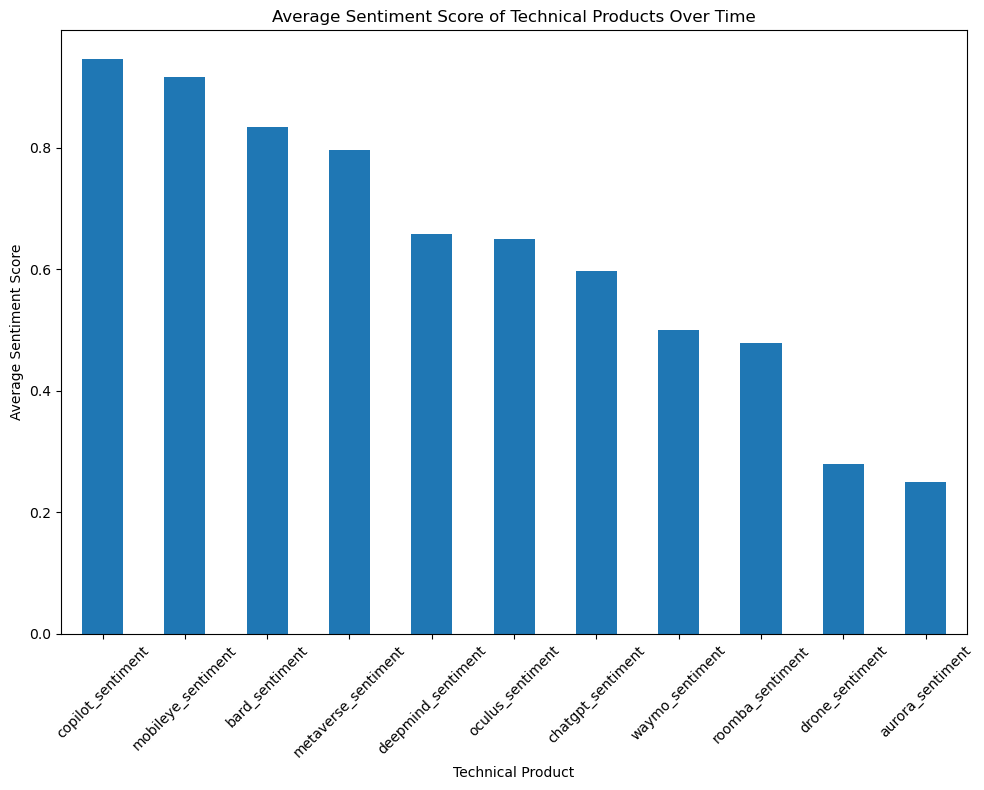
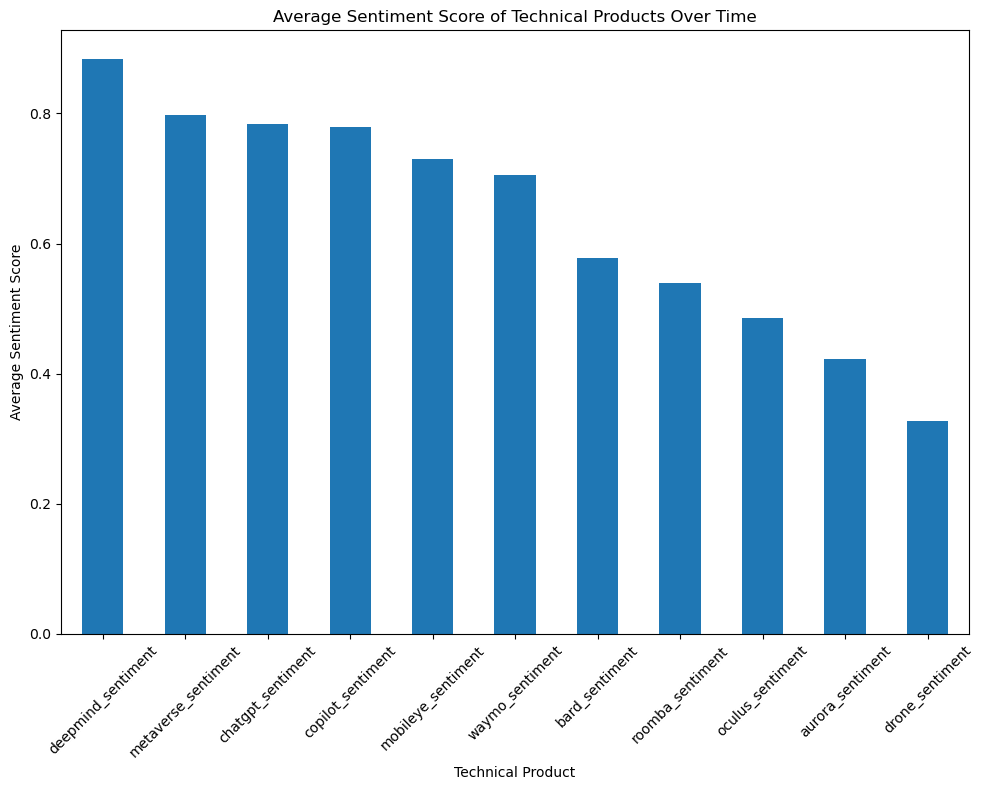
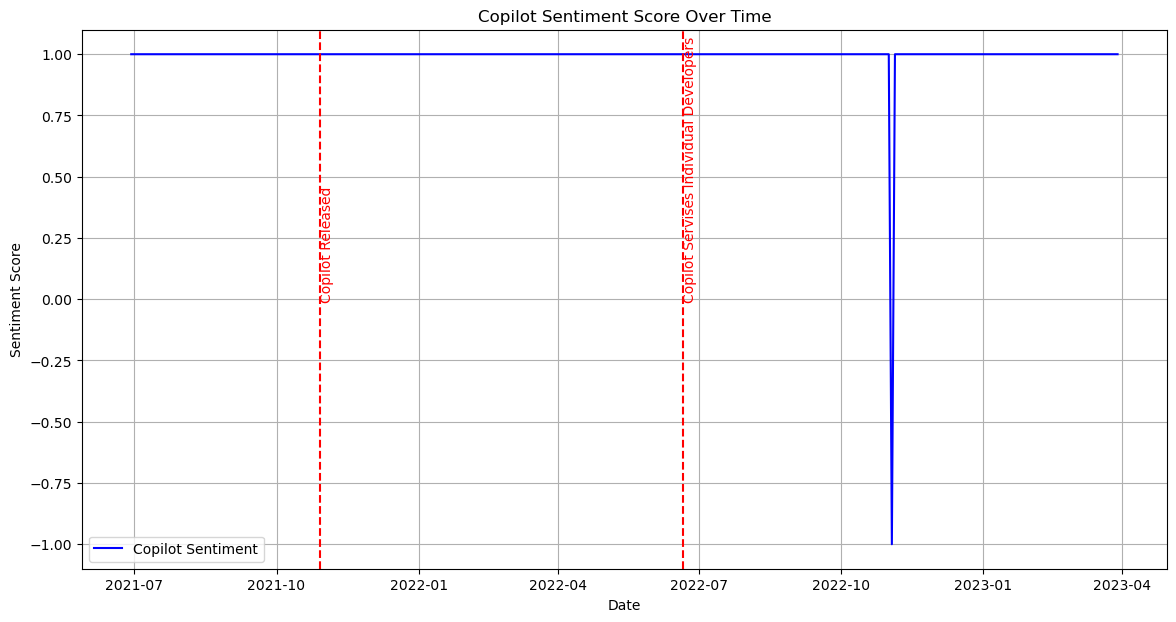
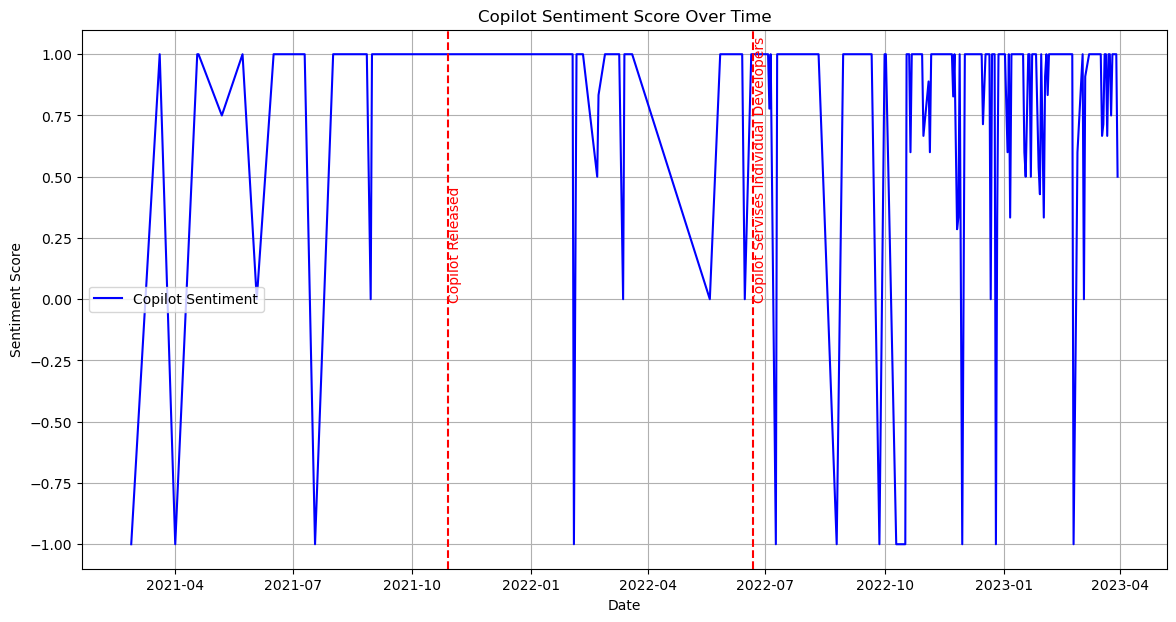
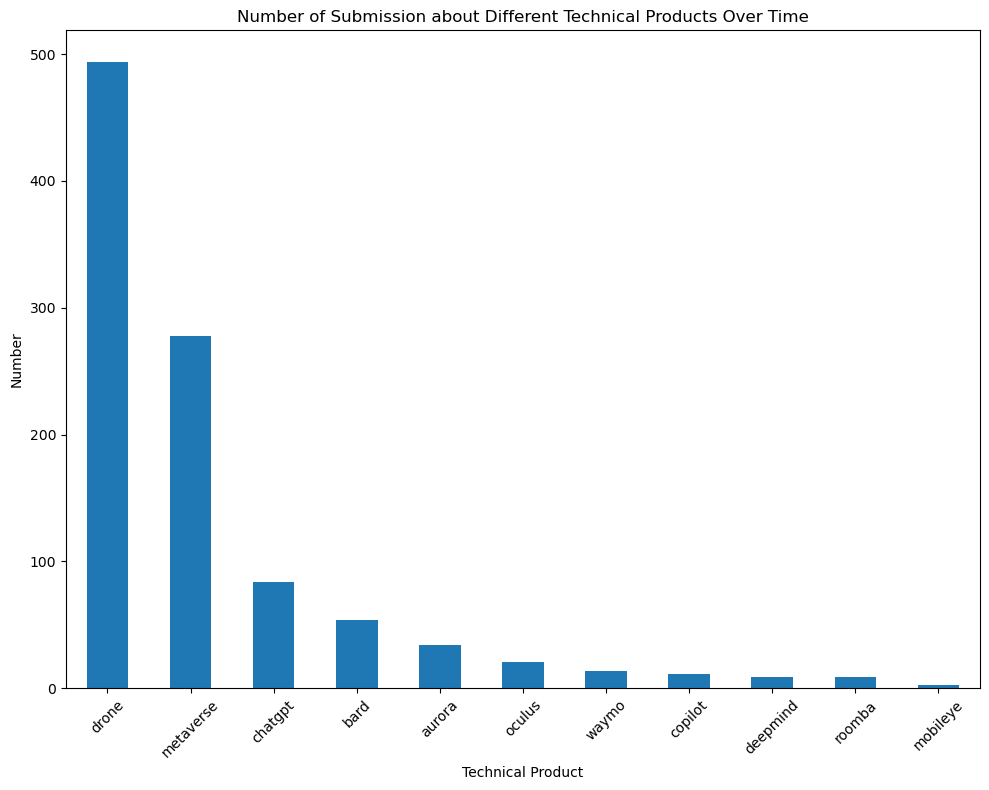
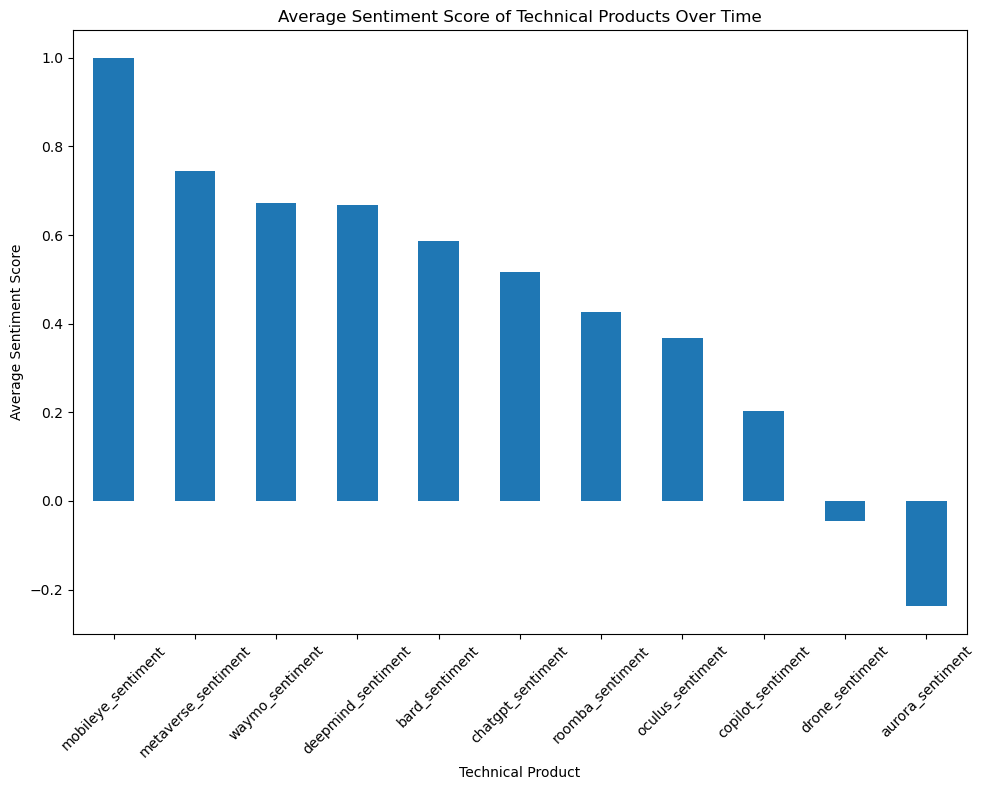
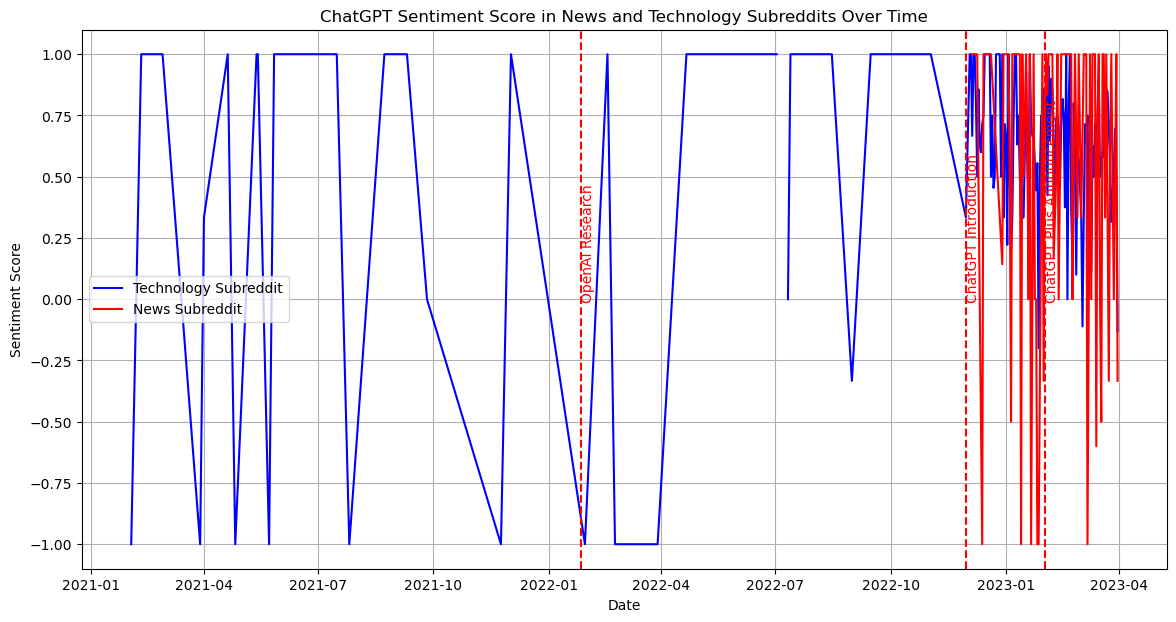
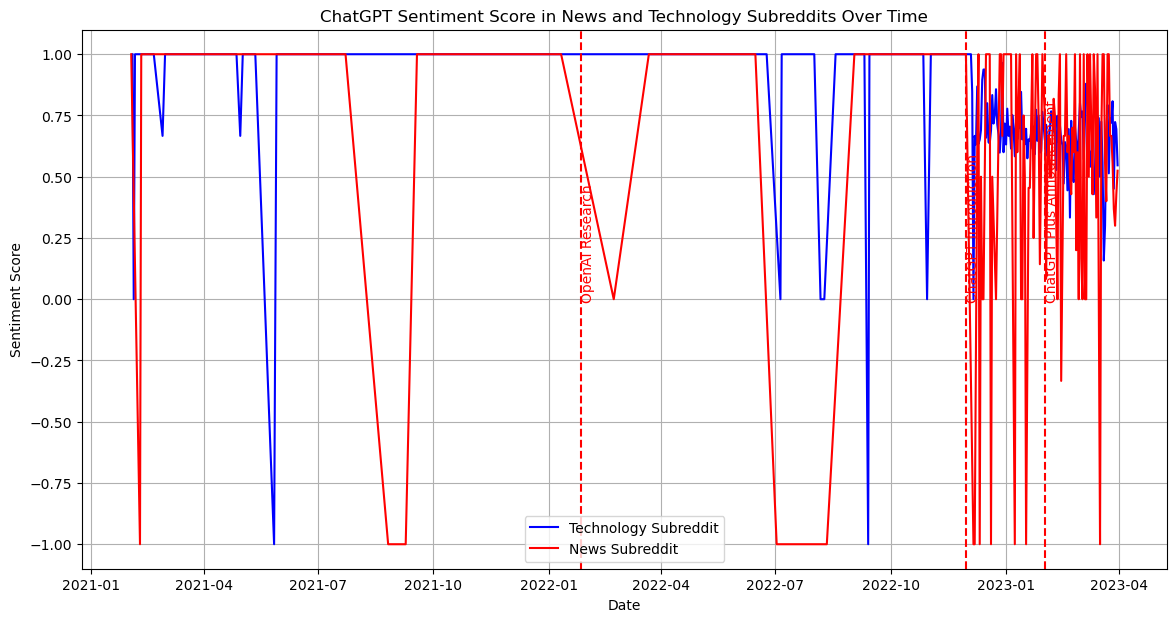
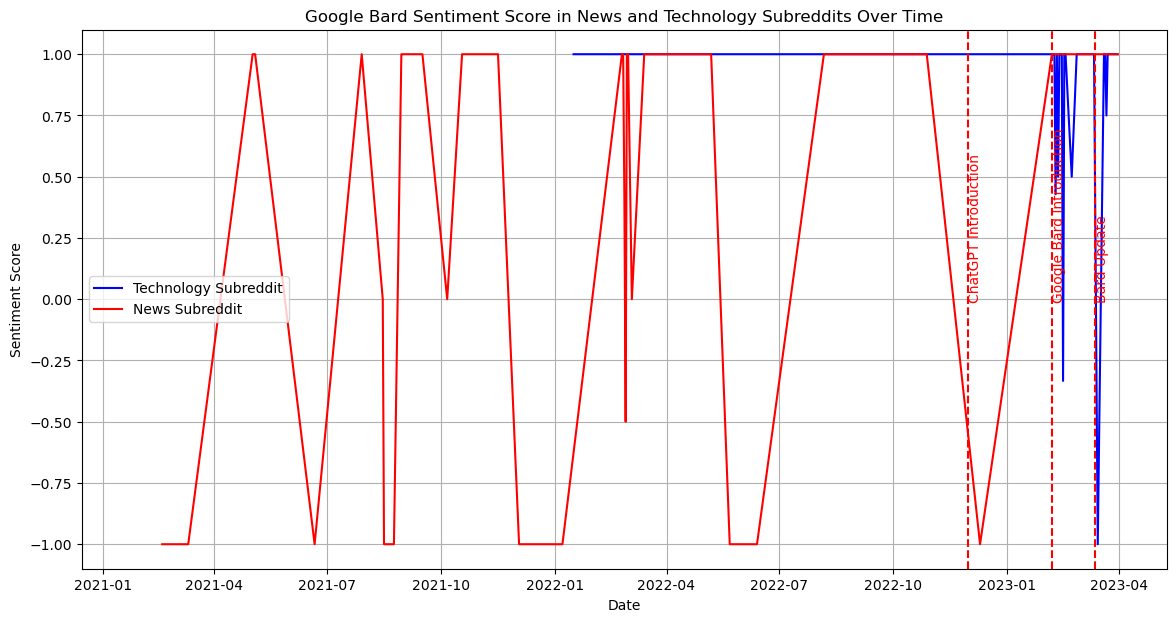
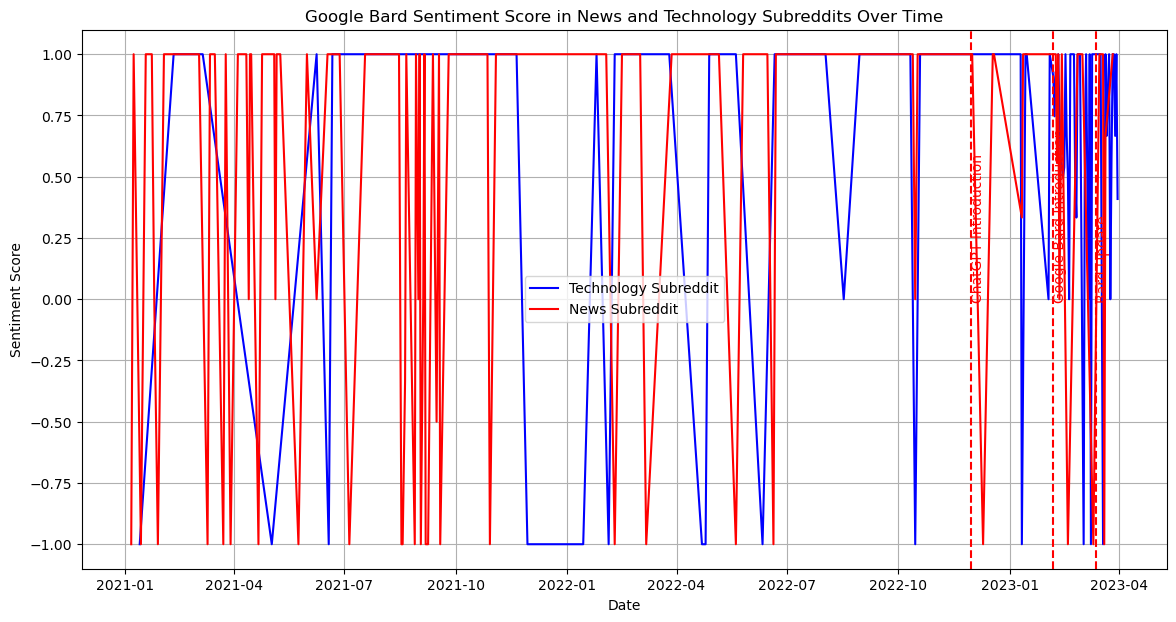
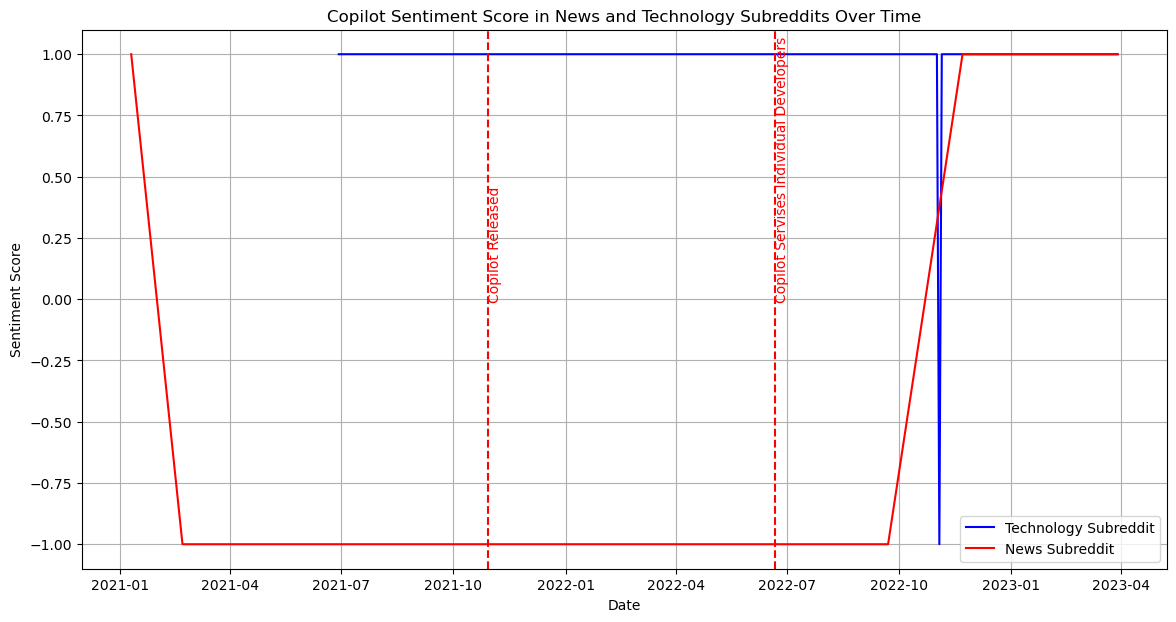
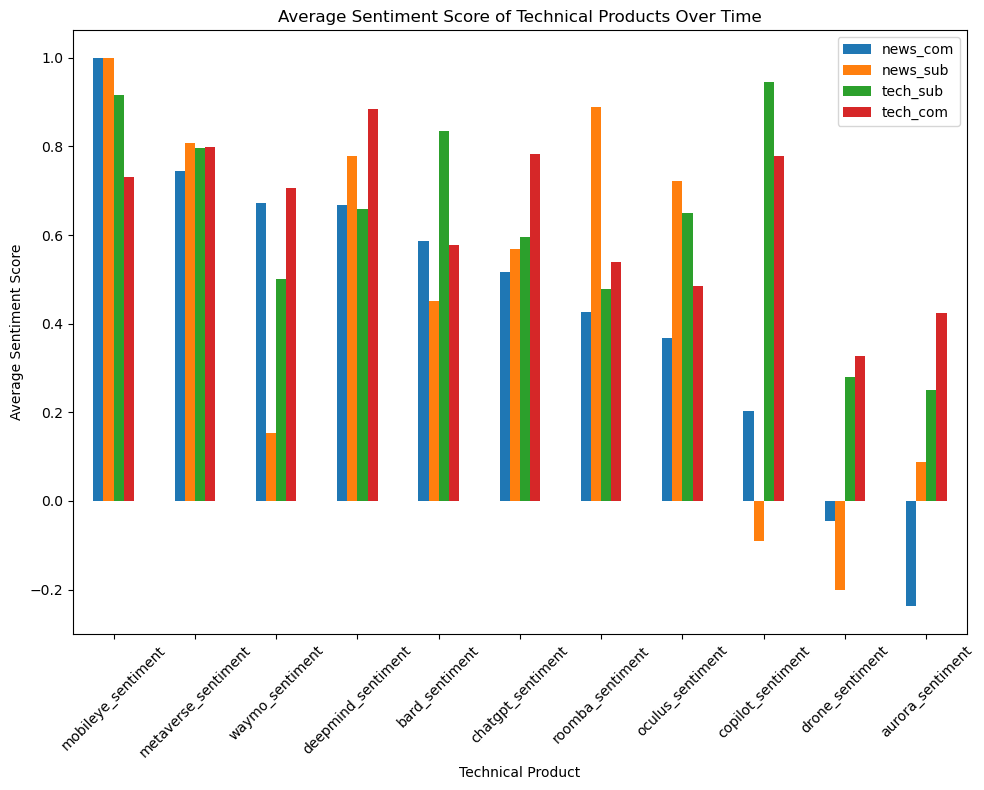
Our next step is to identify the top discussed technical products from these subsets and research how the discussion volume about the detailed technical products changes across time.
From the previous research, we identify major technical items: 1. AI - ChatGPT - Google Bard - Github Copilot 2. AGI - DeepMind 3. Self-Drive - Waymo - Mobileye - Aurora 4. VR - Oculus Quest - Apple ar - Metaverse 5. Robot - Drone - Robot Dog - Humanoid Robot - Roomba