Q10: Predict Submission Subreddit
10. Classifying Reddit Posts: A Machine Learning Approach
Our investigation into Reddit’s digital landscape aimed to classify the origins of posts—whether they stem from r/Technology, reflecting public opinion, or r/News, echoing media narratives. We wanted to pinpoint the linguistic signatures that define each subreddit’s content, thereby enhancing our grasp on how different audience segments interact with tech discussions online.
We harnessed a set of classifier models, examining the text of the posts to classify them accurately. Three distinct models were trained and tested: Logistic Regression, Random Forest, and Naive Bayes—each offering its methodology to crack the code of subreddit classification. All three models performed with relative success, but the Naive Bayes model led the pack with the highest accuracy.
Table 4: Model Evaluation Comparison
| Model | Accuracy |
|---|---|
| Logistic Regression | 0.680 |
| Random Forest | 0.673 |
| Naive Bayes | 0.747 |
Evaluating Model Performance
To evaluate the performance of each model, we looked at the ROC-AUC curve, which is a graphical representation of a model’s diagnostic ability. The curve plots the true positive rate against the false positive rate at various threshold settings.
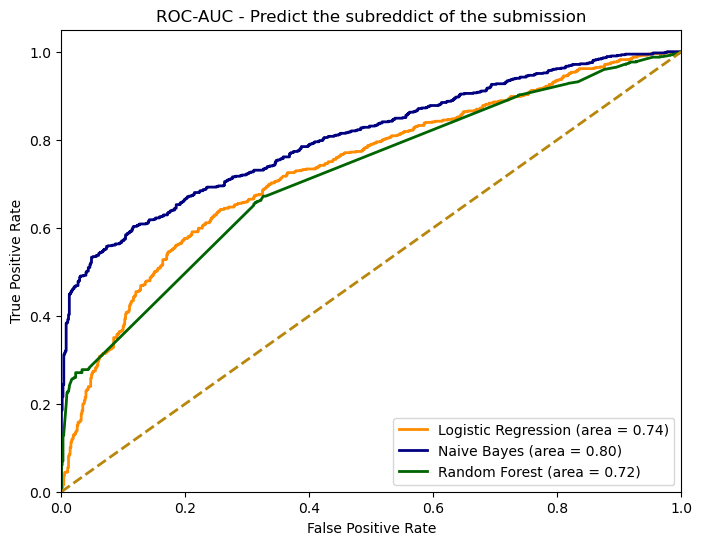
From the plot, the Naive Bayes model achieved the highest area under the curve (AUC), meaning it has the best performance among the three in distinguishing between the posts of the two subreddits. The area under the curve for each model gives us a sense of how well the model is able to classify posts correctly. A model with perfect classification ability would have an area of 1.0, so the closer to this value, the better. The diagonal dashed line represents a baseline random chance. If a model’s curve is closer to this line, it’s considered to be less skillful. Here, all models performed above the line, with Naive Bayes standing out as the most capable of correctly classifying the subreddits based on the post content.